The Crucial Role of Feature Engineering
Understanding the Concept of Feature Engineering
Feature engineering is a crucial step in the machine learning pipeline, often underestimated but profoundly impacting model performance. It involves transforming raw data into features that better represent the underlying patterns and relationships within the dataset. This process goes beyond simply selecting features; it encompasses creating new features from existing ones, handling missing values, and scaling data to optimize model learning. Effectively engineering features is akin to providing a well-structured map to your machine learning algorithm, enabling it to navigate the data landscape more efficiently and achieve higher accuracy.
Feature Selection and Extraction Techniques
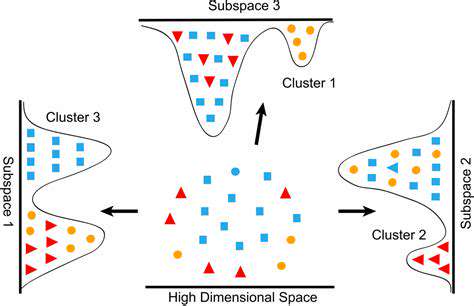
Feature selection is the process of choosing a subset of relevant features from the available data. This can significantly reduce the complexity of the model, improving its training speed and generalization ability. Methods like filter methods, wrapper methods, and embedded methods offer various strategies for selecting the most informative features. Feature extraction, on the other hand, involves creating new features from existing ones. This might include creating polynomial features, interaction features, or applying dimensionality reduction techniques like Principal Component Analysis (PCA). These techniques help to uncover hidden patterns and relationships within the data that might not be apparent in the original features.
Handling Missing Values and Outliers
Missing values and outliers are common issues in real-world datasets. Missing values can significantly impact model performance, and their presence can lead to biased or inaccurate results. Appropriate handling of missing values is crucial. Strategies include imputation using mean, median, or more sophisticated techniques like k-nearest neighbors. Outliers, which are data points that deviate significantly from the rest of the data, can also skew model results. Identifying and handling outliers appropriately is essential for building a robust and reliable machine learning model, which could involve techniques like capping or winsorizing to limit their impact.
Data Transformation and Scaling Techniques
Data transformation and scaling techniques are essential for preparing data for machine learning models. Different algorithms perform best with specific types of data. For example, some algorithms are sensitive to the scale of features. Standardization, normalization, and other scaling techniques can ensure that all features contribute equally to the model's learning process. These transformations can significantly improve model performance by creating a more optimal learning environment for the algorithm. Data transformation, such as log transformations or one-hot encoding, can also help to reveal hidden patterns in data and create more informative features.
The Impact of Feature Engineering on Model Performance
Effective feature engineering directly impacts the performance of machine learning models. By creating informative and relevant features, models can learn more accurately from the data. This leads to improved prediction accuracy, better generalization to unseen data, and faster training times. Poor feature engineering, on the other hand, can lead to inaccurate predictions, poor model performance, and increased complexity. The quality of the features often dictates the success of the entire machine learning project. A thorough and well-thought-out feature engineering process is essential for achieving the desired results in any machine learning task.
Handling Missing Data and Outliers
Understanding Missing Data
Missing data is a common problem in datasets used for machine learning. It can significantly impact the performance of your models if not handled appropriately. Understanding the nature and extent of missingness is crucial. Are the missing values randomly distributed or are they concentrated in specific categories or observations? Knowing this will guide your decision-making process regarding imputation strategies. Identifying patterns in missing values can uncover underlying factors that may be influencing the data and provide insights that could lead to valuable feature engineering opportunities. For example, missing values for a specific feature might correlate with a particular customer segment, prompting a deeper investigation into the reasons behind these missing values.
Different approaches to handling missing data include deletion (listwise or pairwise), imputation (mean, median, mode, regression-based), and more sophisticated techniques like k-nearest neighbors imputation. The best approach depends on the characteristics of the data and the specific machine learning algorithm you intend to use.
Identifying and Dealing with Outliers
Outliers are extreme values that deviate significantly from the rest of the data. They can skew statistical measures like the mean and standard deviation, and they can negatively impact the accuracy and reliability of your machine learning models. Identifying outliers requires careful consideration of the context of your data. Techniques like box plots, scatter plots, and statistical methods such as Z-scores and IQR (interquartile range) can help visualize and pinpoint these values.
Once outliers are identified, appropriate strategies for handling them need to be considered. Options include removing them if they are errors or do not represent the typical data distribution, transforming the data to reduce their impact, or using robust statistical methods that are less sensitive to extreme values.
Imputation Techniques for Missing Values
Imputation methods involve replacing missing values with estimated values. Simple methods like mean, median, or mode imputation are straightforward but can lead to inaccuracies if the missing data is not randomly distributed. More sophisticated techniques like regression-based imputation, where missing values are predicted using a regression model trained on the complete data, can provide more accurate estimations, especially when there are relationships between the missing feature and other features.
Advanced Techniques for Missing Value Handling
For complex datasets with intricate relationships between features, more advanced imputation techniques such as k-nearest neighbors (KNN) imputation or machine learning models can be used. KNN imputation estimates the missing value based on the values of the k-nearest neighbors in the feature space. Machine learning models, like decision trees or random forests, can be trained to predict the missing values.
Feature Engineering Strategies for Handling Missing Data
One powerful technique is to create new features that incorporate information about missing data. For example, you could create a binary feature indicating whether a value is missing for a particular variable. This feature can then be used by the machine learning algorithm to learn how missing values influence the target variable. Alternatively, you can categorize missing values based on the underlying reasons for the missingness.
Impact of Missing Data and Outliers on Model Performance
Missing data and outliers can have a profound impact on the performance of machine learning models. They can lead to biased estimates, inaccurate predictions, and ultimately decreased model accuracy and reliability. It's critical to evaluate the impact of these data issues on the specific algorithm you are using. For example, linear regression models are particularly sensitive to outliers.
Validation and Evaluation of Imputation Strategies
After imputing missing values or handling outliers, it's crucial to validate the effectiveness of your chosen strategy. This involves comparing the performance of the model trained on the imputed data to the performance of the model trained on the original data, or a subset of the data where there are no missing values. Careful evaluation ensures that the imputation techniques do not introduce biases or create artifacts that negatively impact the performance of the model, and that the chosen strategy does not lead to a significant loss of information.
Enhancing Model Performance through Feature Scaling

Data Preprocessing Techniques
Effective data preprocessing is crucial for improving model performance. Cleaning and transforming raw data into a suitable format significantly impacts the model's ability to learn and generalize. This involves handling missing values, outliers, and inconsistencies in the dataset. Properly scaling numerical features can also prevent features with larger values from dominating the learning process, ensuring all features contribute fairly to the model's understanding.
Techniques like standardization or normalization can significantly improve model performance by ensuring features have similar ranges. Furthermore, careful consideration of feature engineering, such as creating new features from existing ones, can unveil hidden patterns and relationships within the data, leading to a more robust model.
Model Selection and Tuning
Choosing the appropriate machine learning model for a specific task is a critical step in achieving optimal performance. Different models excel in different scenarios, and selecting the right one can drastically impact the accuracy and efficiency of the outcome. Consider factors like the nature of the data, the desired outcome, and the computational resources available when making your selection.
Once a model is selected, hyperparameter tuning is essential for maximizing its performance. Hyperparameters control the model's learning process, and finding the optimal values for these parameters often requires experimentation and careful consideration. Techniques like grid search or random search can be employed to systematically explore different combinations of hyperparameters and identify the best-performing configuration.
Feature Engineering Strategies
Feature engineering is the process of creating new features from existing ones to improve model performance. This can involve combining existing features, transforming them using mathematical operations, or creating entirely new features that capture relevant information from the data.
By extracting meaningful insights from the data, we can enhance the model's ability to identify patterns and relationships. This process often involves domain expertise and knowledge of the specific application. Careful consideration of the domain context is essential for creating relevant and informative features. Moreover, feature engineering helps in reducing the dimensionality of the data, which can further improve model performance and efficiency.
Regularization Techniques
Regularization techniques are essential for preventing overfitting in machine learning models. Overfitting occurs when a model learns the training data too well, leading to poor generalization on unseen data. This is a common problem in machine learning and can significantly reduce the model's accuracy on new, unseen data points.
Regularization methods add a penalty term to the model's loss function, encouraging simpler models and reducing the model's complexity. Techniques like L1 and L2 regularization can help prevent overfitting and improve the model's ability to generalize. By reducing the model's complexity, these methods also help improve the interpretability of the model's predictions.
Data Augmentation Strategies
Limited data can significantly hinder the performance of machine learning models. Data augmentation techniques aim to increase the size and diversity of the training dataset by creating synthetic data points. This can be particularly helpful when dealing with datasets that are small or imbalanced.
By artificially expanding the dataset, data augmentation can help the model learn more effectively and improve its ability to generalize. Methods like image transformations (rotation, flipping, cropping) or text augmentation can be employed to generate new data points that are similar to the original ones. This process can provide more robust training examples for the model.
Evaluation Metrics and Validation
Properly evaluating the performance of a machine learning model is crucial for understanding its effectiveness. This involves selecting appropriate evaluation metrics and conducting rigorous validation procedures. Common metrics include accuracy, precision, recall, F1-score, and AUC-ROC, each providing a different perspective on the model's performance.
Using techniques such as cross-validation ensures a more reliable assessment of the model's performance on unseen data. This process involves splitting the data into multiple subsets and training and evaluating the model on different combinations of these subsets. This allows for a more comprehensive evaluation of the model's generalization ability and reduces the risk of overfitting to the training set.