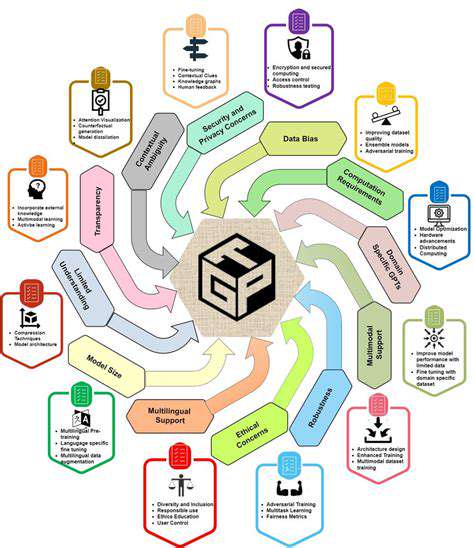
Beyond Simple Transformations: Advanced Augmentation Techniques

Beyond the Basics of Data Transformation
Data transformation is more than just changing the format of your data. It encompasses a wide array of techniques, from simple data cleaning to complex feature engineering. Understanding these different approaches is crucial for building accurate and reliable models. This process often involves handling missing values, standardizing variables, and converting data types to ensure compatibility with various analytical tools.
Effective data transformation is not just about making the data look pretty; it's about preparing it for meaningful analysis. This involves identifying patterns, relationships, and anomalies within the dataset that might otherwise be hidden.
Feature Engineering for Deeper Insights
feature engineering is a critical step in data transformation. It involves creating new features from existing ones to improve model performance and uncover hidden relationships. This process can involve combining existing variables, extracting relevant information from text or images, or creating derived measures.
By carefully crafting new features, you can significantly enhance the predictive power of your models. This often requires domain expertise and creative problem-solving to determine which new features will be most valuable.
Handling Missing Values with Robust Strategies
Missing data is a common challenge in data analysis. Effective strategies for handling missing values are essential to prevent bias and maintain data integrity. Different methods exist, ranging from simple imputation techniques to more complex models that predict missing values based on available data.
Choosing the right method depends heavily on the nature of the missing data and the specific analytical task. Careful consideration of the implications of each method is crucial to avoid introducing errors into the analysis.
Data Normalization and Standardization for Improved Modeling
Data normalization and standardization are essential techniques for ensuring that different variables in a dataset have similar scales and distributions. This is crucial because many machine learning algorithms are sensitive to the range of values of different features.
These techniques help prevent features with larger values from dominating the model and allow all features to contribute equally to the analysis.
Data Reduction Techniques for Efficiency
Data reduction techniques are used to simplify the dataset while retaining important information. This can involve dimensionality reduction methods like principal component analysis (PCA) or feature selection methods that identify the most relevant features.
Data reduction not only improves efficiency in model training and inference but can also make it easier to visualize and interpret the data.
Advanced Data Transformation Techniques
Beyond basic transformations, advanced techniques like binning, discretization, and one-hot encoding can significantly improve data quality and model performance. Binning, for example, can group continuous variables into discrete categories, while discretization transforms continuous variables into categorical ones.
One-hot encoding converts categorical variables into numerical representations, which is often necessary for machine learning algorithms. These techniques are crucial for building accurate and reliable predictive models.
Evaluating the Impact of Transformations
Evaluating the impact of data transformations is critical to ensure the chosen methods improve rather than hinder the analysis. This involves assessing the quality of the transformed data using metrics like data distribution, outliers, and correlations. Careful monitoring of these factors is critical for effective data transformation.
Comparing model performance before and after transformations allows for a quantitative assessment of the impact of the changes. This step provides insights into the optimal approach to data transformation for a given dataset and analytical task.
Applications Across Diverse Domains
Image Enhancement and Recognition
Generative AI models excel at enhancing the quality and diversity of image datasets, a crucial aspect of training robust image recognition systems. By generating synthetic images that resemble real-world data but with variations in lighting, pose, and object attributes, generative AI can significantly increase the size and complexity of training datasets. This leads to improved model accuracy and generalization capabilities, making the models more resilient to unseen variations in real-world images.
Furthermore, generative AI can be used to create entirely new image data for specific tasks or scenarios where real-world data is scarce or expensive to collect. This is particularly valuable in medical imaging where creating diverse representations of diseases or anatomical structures can aid in the development of more accurate diagnostic tools.
Natural Language Processing Enhancements
In natural language processing (NLP), generative AI models can create vast amounts of synthetic text data, mirroring human writing styles and incorporating diverse topics and sentiments. This augmented dataset can significantly improve the performance of NLP models in various tasks, such as sentiment analysis, text summarization, and machine translation. By providing models with more comprehensive and nuanced language examples, the augmented datasets lead to more accurate and contextually aware outputs.
The application extends to generating different writing styles, mimicking specific authors, or even creating fake news articles to train models on detecting misinformation, thereby improving their ability to discern real from fabricated content.
Drug Discovery and Material Science
Generative AI's ability to create synthetic data has profound implications for drug discovery and material science. By generating diverse molecular structures and simulating their properties, researchers can accelerate the identification of promising drug candidates and novel materials with specific functionalities. This process significantly reduces the time and resources required for experimental testing, as the AI can predict the outcomes of various chemical reactions and interactions.
The creation of synthetic molecules and materials is a critical step in understanding their properties and potential applications. This capability is especially valuable when dealing with complex systems where experimental data is limited or expensive to obtain, potentially revolutionizing the development of new medicines and advanced technologies.
Customer Service and Chatbots
Generative AI can augment customer service datasets by creating synthetic conversations, encompassing various customer inquiries, complaints, and feedback. This synthetic data can be used to train chatbots and other customer service agents, equipping them to handle a wider range of scenarios and provide more accurate and personalized responses. The creation of diverse conversational scenarios allows the models to learn from a broader range of interactions, leading to improved customer satisfaction and efficiency.
Financial Modeling and Risk Assessment
In the financial sector, generative AI can create synthetic financial data, such as stock prices, market trends, and economic indicators. This approach can be used to train models for risk assessment, fraud detection, and portfolio optimization. By generating realistic, yet diverse, datasets, generative AI can improve the accuracy and robustness of financial models, leading to more effective risk management strategies. This is especially crucial in volatile markets where traditional data sources may not reflect the complexities of real-time conditions.
This synthetic data enables more comprehensive testing of financial models, allowing for identification of vulnerabilities and potential weaknesses, ultimately improving predictive accuracy and supporting more informed decision-making within the financial sector.