Introduction to AI in Credit Risk

Understanding the Fundamentals of Artificial Intelligence
The financial sector is witnessing a paradigm shift with the integration of artificial intelligence into credit risk evaluation processes. Traditional assessment methods are being augmented by sophisticated analytical capabilities that can process information at unprecedented scales. This evolution enables financial institutions to make more informed judgments about borrower reliability.
What sets modern analytical approaches apart is their capacity to synthesize information from diverse streams. While conventional systems might examine a handful of financial indicators, contemporary solutions incorporate behavioral data, digital footprints, and alternative financial markers. This multidimensional analysis paints a more complete picture of an applicant's fiscal health and repayment capacity, fundamentally changing risk assessment methodologies.
Machine Learning Models in Credit Scoring
At the heart of these advancements are self-improving computational models that refine their predictive capabilities through exposure to historical data. These systems identify subtle relationships between numerous variables and credit performance, continuously enhancing their evaluation frameworks.
Particularly noteworthy are advanced pattern recognition systems like multilayer perceptrons and kernel-based classifiers, which excel at detecting intricate correlations that might escape human analysts or simpler statistical models. Their ability to process enormous datasets allows for the identification of nuanced risk indicators that traditional credit scoring systems might overlook.
Data Sources and Their Importance
The efficacy of modern credit evaluation systems hinges on both the breadth and quality of input information. Optimal performance requires accessing diverse data streams, from conventional financial statements to digital behavioral patterns and alternative financial records.
Maintaining data integrity and comprehensiveness is absolutely critical. Inadequate or erroneous data can distort risk predictions, potentially leading to suboptimal lending decisions. Equally important are robust protocols for data protection and privacy compliance, ensuring both regulatory adherence and consumer trust in these advanced analytical systems.
The Impact on Lending Decisions
The implementation of these sophisticated evaluation methods is reshaping credit allocation processes. By generating more precise risk profiles, financial institutions can optimize their lending strategies, potentially reducing non-performing assets while improving portfolio performance.
The operational efficiencies gained are transformative. Automated risk assessment significantly accelerates application processing, enabling faster credit decisions while maintaining rigorous evaluation standards. This operational streamlining can democratize access to financial products for qualified applicants who might have been underserved by traditional systems.
Ethical Considerations and Future Trends
While the potential benefits are substantial, responsible implementation requires careful attention to ethical implications. Ensuring algorithmic fairness, operational transparency, and accountability mechanisms is essential to prevent unintended discrimination and maintain public confidence in automated decision-making systems.
Looking ahead, the trajectory of these technologies points toward increasingly sophisticated applications. Continued advancements in analytical models and data integration capabilities promise further refinements in risk assessment accuracy and efficiency, potentially fostering more inclusive financial ecosystems.
Machine Learning Algorithms for Enhanced Predictive Power
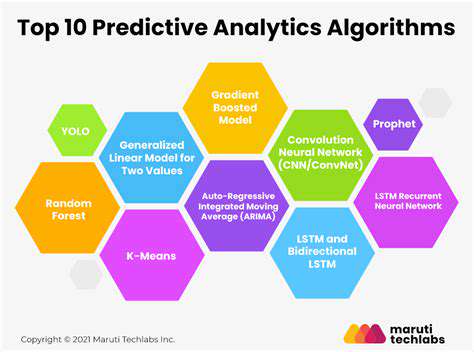
Supervised Learning Algorithms
These predictive models operate on annotated training sets where each observation includes both input parameters and known outcomes. Common implementations include generalized linear models, maximum-margin classifiers, and recursive partitioning methods, each suited to different predictive challenges ranging from continuous value estimation to categorical classification.
The fundamental objective is to develop a mathematical relationship that accurately transforms input variables into predicted outputs, allowing for reliable forecasting when presented with novel data instances.
Unsupervised Learning Algorithms
When working with unstructured data lacking predefined classifications, these exploratory techniques identify inherent groupings and relationships. Partition-based clustering and agglomerative hierarchical methods represent powerful tools for discovering natural data segmentations, proving particularly valuable for market segmentation and behavioral pattern analysis.
These approaches shine when the underlying data structure isn't immediately evident, revealing latent patterns that can inform strategic decision-making and hypothesis generation.
Reinforcement Learning Algorithms
These adaptive systems develop decision-making policies through environmental interaction and feedback mechanisms. Temporal difference learning and neural network-based value estimation methods have demonstrated particular effectiveness in dynamic environments requiring sequential decision optimization, from automated trading systems to robotic control applications.
The learning process resembles trial-and-error refinement, where the system gradually improves its strategy based on performance feedback, ultimately converging on optimal decision pathways.
Deep Learning Algorithms
Multilayered neural architectures have revolutionized pattern recognition across multiple domains. Hierarchical feature extractors have transformed visual data processing, while specialized recurrent architectures handle temporal sequences with remarkable proficiency, enabling breakthroughs in everything from financial time-series forecasting to natural language understanding.
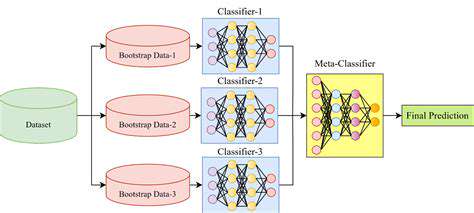
Ensemble Learning Methods
By strategically combining multiple predictive models, these techniques achieve superior performance through collective decision-making. Parallel model aggregation and sequential enhancement approaches leverage the complementary strengths of individual learners, reducing variance and bias while improving overall predictive stability.
This collective approach often outperforms single-model solutions, particularly when dealing with complex datasets where different models may capture different aspects of the underlying patterns.
Model Evaluation and Selection
Rigorous performance assessment is paramount for ensuring reliable real-world deployment. Appropriate metric selection varies by application context, with classification tasks requiring different evaluation frameworks than regression problems. The art of model selection balances algorithmic characteristics with operational requirements and data properties, with resampling techniques playing a crucial role in preventing over-optimistic performance estimates.
Feature Engineering and Selection
Predictive model quality fundamentally depends on input representation. Sophisticated transformation techniques can reveal latent predictive signals, while dimensionality reduction focuses model attention on the most informative variables, improving both performance and interpretability.
Thoughtful feature processing can dramatically enhance model effectiveness by eliminating noise and highlighting the most relevant predictive signals within complex datasets.